|
Baiqiao Yin「尹柏乔」
Hi! I'm Baiqiao Yin. Most recently, I had the great fortune to work with Manling Li at Northwestern University, where we pushed the boundaries of spatial intelligence.
Previously, I got my B.Eng. in Intelligent Science and Technology in SYSU, where I worked closely with Xiaodan Liang. |

|
Internship
|
📝Research💬My research interests lie in spatial intelligence. Currently, my focus is on designing spatial intelligence agents with the following capabilities:
|
|
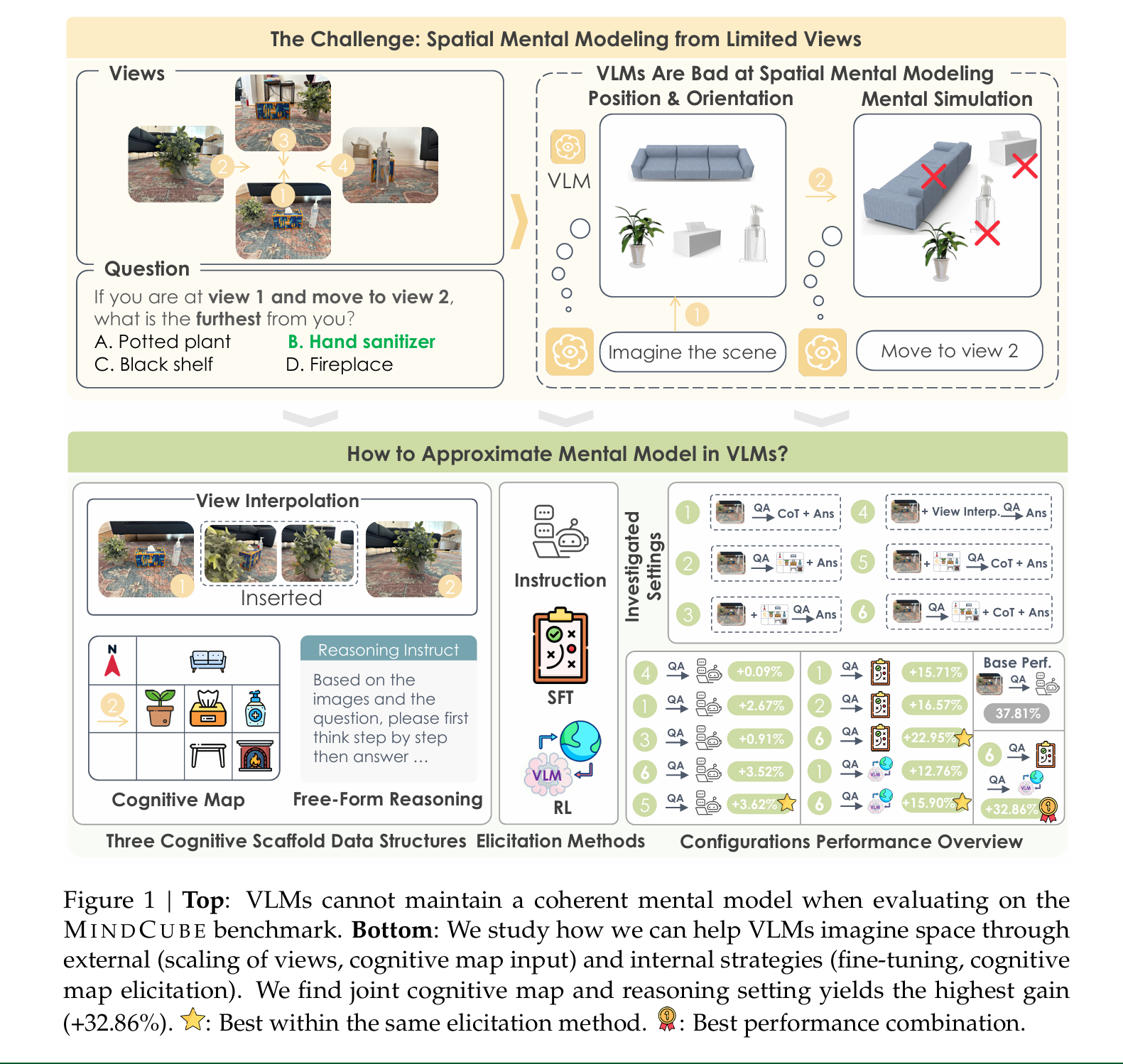
Spatial Mental Modeling from Limited Views
Baiqiao Yin*, Qineng Wang*, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, Saining Xie, Manling Li, Jiajun Wu, Li Fei-Fei (Best Paper)ICCV Workshop on Structural Priors for Vision (SP4V)/ (Oral)ACMMM Workshop on Multimodal Foundation Models for Spatial Intelligence (MFMSI), 2025 project page / arXiv Key Takeaway: Guiding VLMs to first generate cognitive maps, then reason upon them, is an effective approach to approximate spatial mental modeling with limited views. |

|
⭐Awesome Spatial Intelligence in VLM (500+ Stars)
Baiqiao Yin GitHub Repository, 2024-Present GitHub A curated collection of papers, datasets, and resources on spatial intelligence in vision-language models, maintained and regularly updated with the latest research developments. |
|
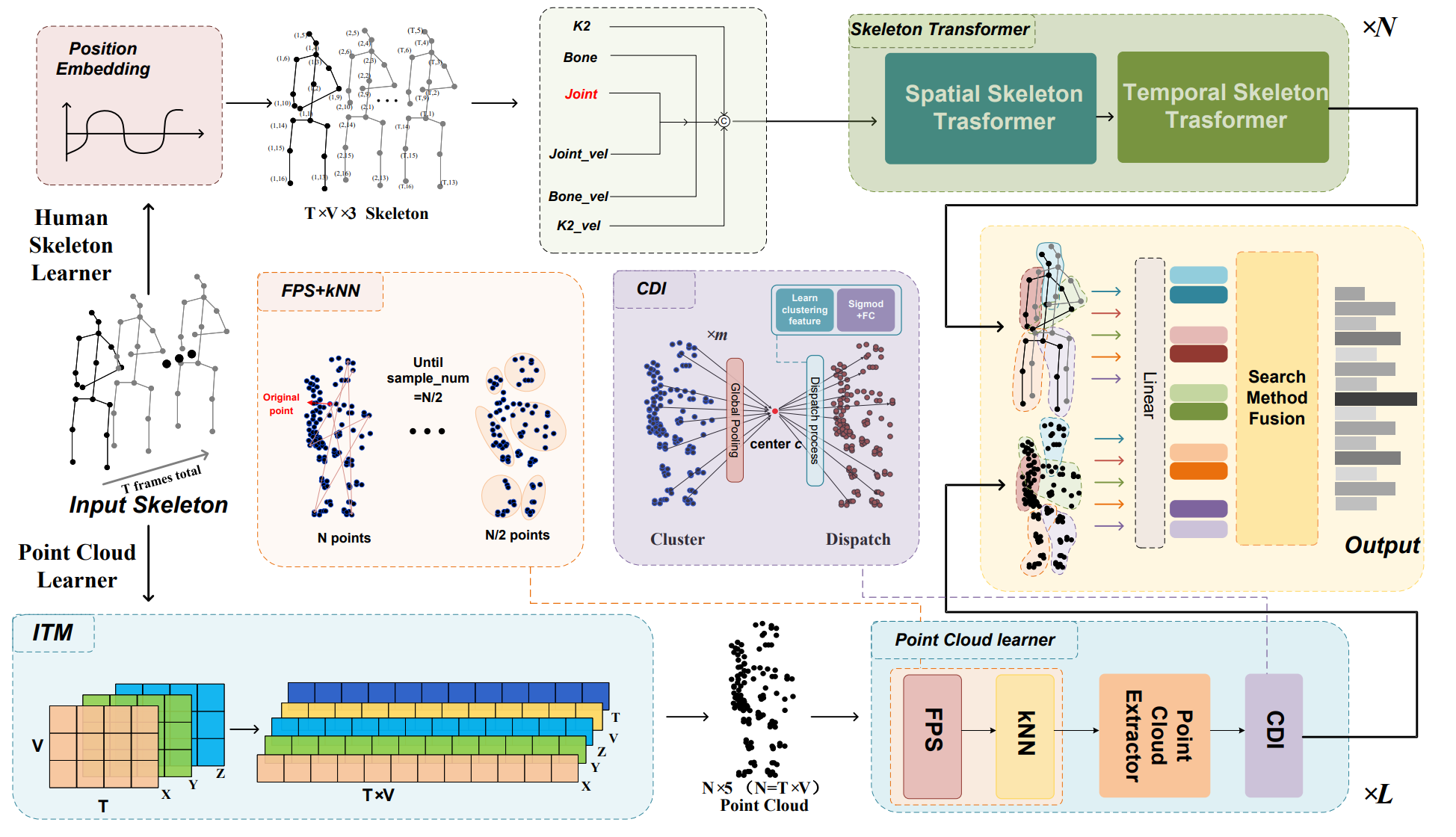
Skeleton2Point: Recognizing Skeleton-Based Actions as Point Clouds
Baiqiao Yin, Jiaying Lin, Jiajun Wen, Yue Li, Jinfu Liu, Yanfei Wang, Mengyuan Liu IROS, 2025(Oral) project page / paper Regard skeleton joints as point cloud via incorporating the position information of skeletons into point cloud methods, demonstrating the validity of modeling position relationships with 3D coordinates. |
|
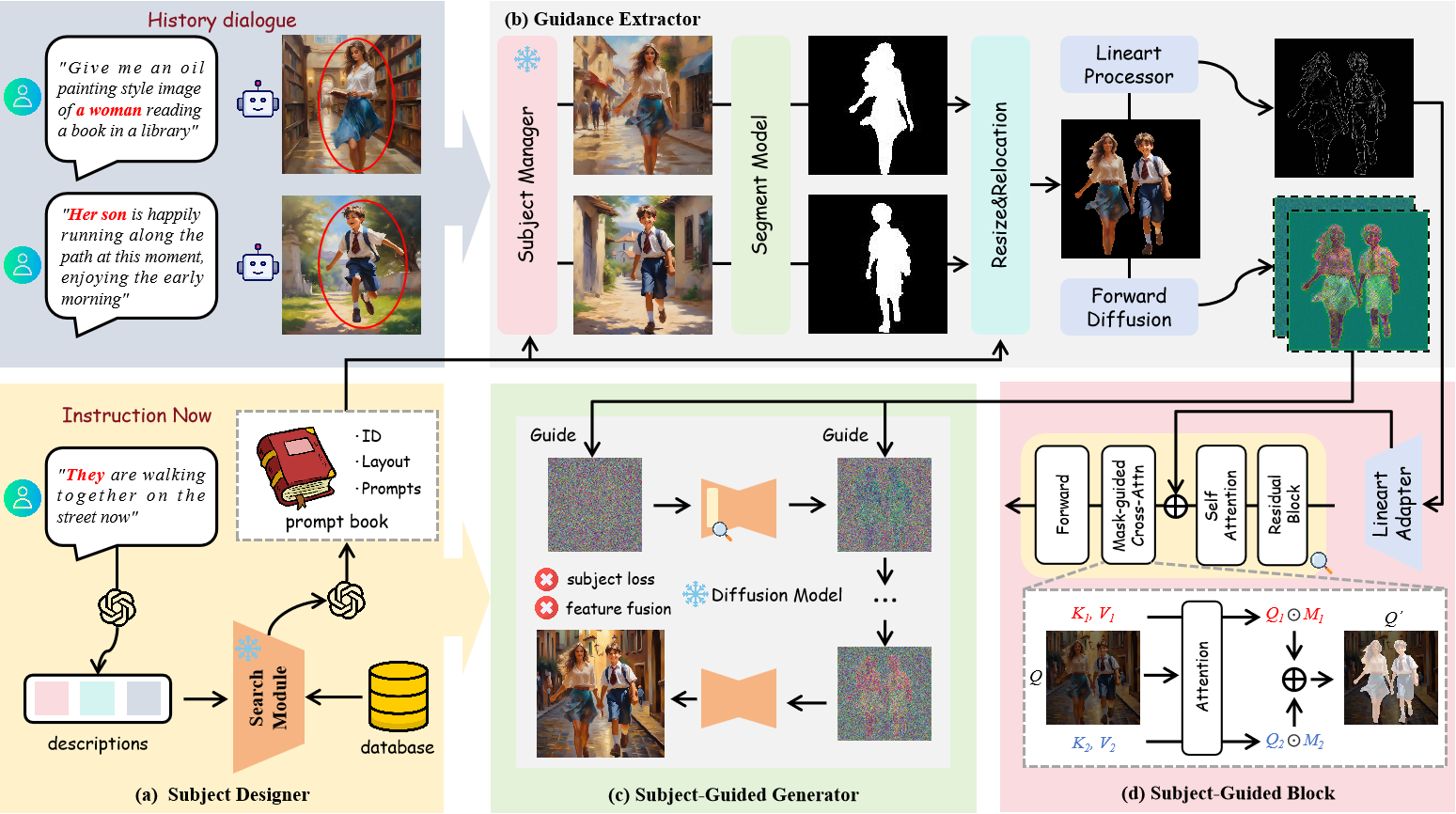
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Junhao Cheng, Baiqiao Yin, Kaixin Cai, Minbin Huang, Hanhui Li, Yuxin He, Xi Lu, Yue Li, Yifei Li, Yiqiang Yan, Xiaodan Liang arxiv, 2024 project page / arxiv Theatergen can interact with users to consistently generate images over multiple Turns. |
|
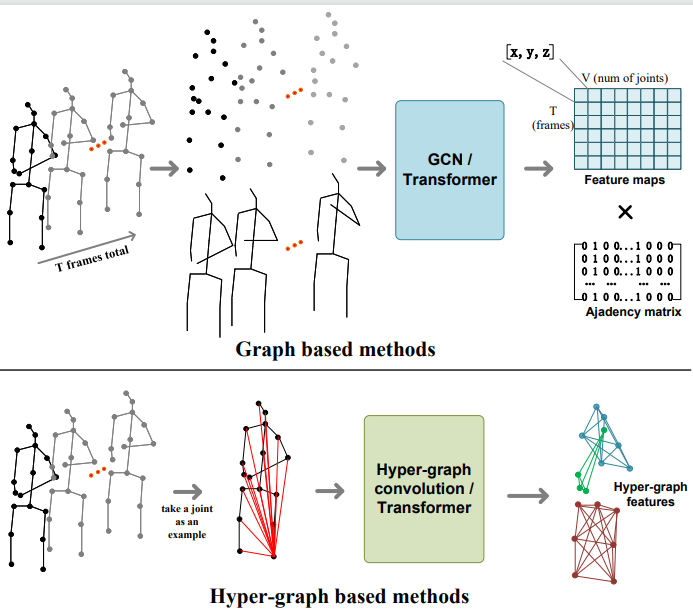
HDBN: A Novel Hybrid Dual-branch Network for Robust Skeleton-based Action Recognition
Jinfu Liu*, Baiqiao Yin*, Jiaying Lin, Jiajun Wen, Yue Li, Mengyuan Liu ICME, 2024 code / paper Benefits from the graph convolutional network's proficiency in handling graph-structured data and the powerful modeling capabilities of Transformers for global information. |
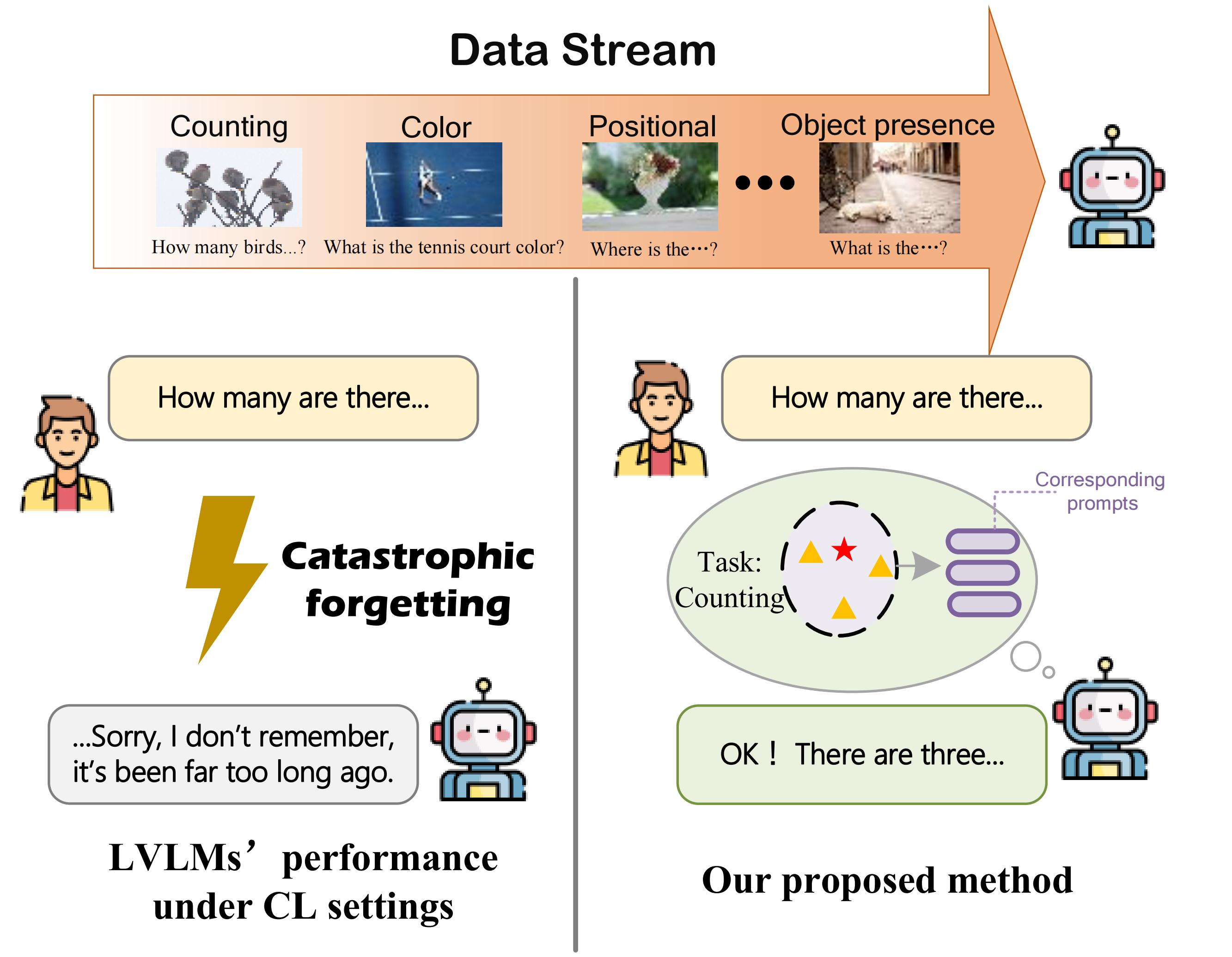
|
LVLM-CL: Make Large Vision-Language Models Work Better Under Continual Learning Settings
Baiqiao Yin, Tech Report paper Devise a task-specific continual learning setting especially for LVLMs by classifying the instruction tuning data for the second finetune process of LVLMs into several different tasks |